
In this paper, we present our method for neural face reenactment, called HyperReenact, that aims to generate realistic talking head images of a source identity, driven by a target facial pose. Existing state-of-the-art face reenactment methods train controllable generative models that learn to synthesize realistic facial images, yet producing reenacted faces that are prone to significant visual artifacts, especially under the challenging condition of extreme head pose changes, or requiring expensive few-shot fine-tuning to better preserve the source identity characteristics. We propose to address these limitations by leveraging the photorealistic generation ability and the disentangled properties of a pretrained StyleGAN2 generator, by first inverting the real images into its latent space and then using a hypernetwork to perform: (i) refinement of the source identity characteristics and (ii) facial pose re-targeting, eliminating this way the dependence on external editing methods that typically produce artifacts. Our method operates under the one-shot setting (i.e., using a single source frame) and allows for cross-subject reenactment, without requiring any subject-specific fine-tuning. We compare our method both quantitatively and qualitatively against several state-of-the-art techniques on the standard benchmarks of VoxCeleb1 and VoxCeleb2, demonstrating the superiority of our approach in producing artifact-free images, exhibiting remarkable robustness even under extreme head pose changes.
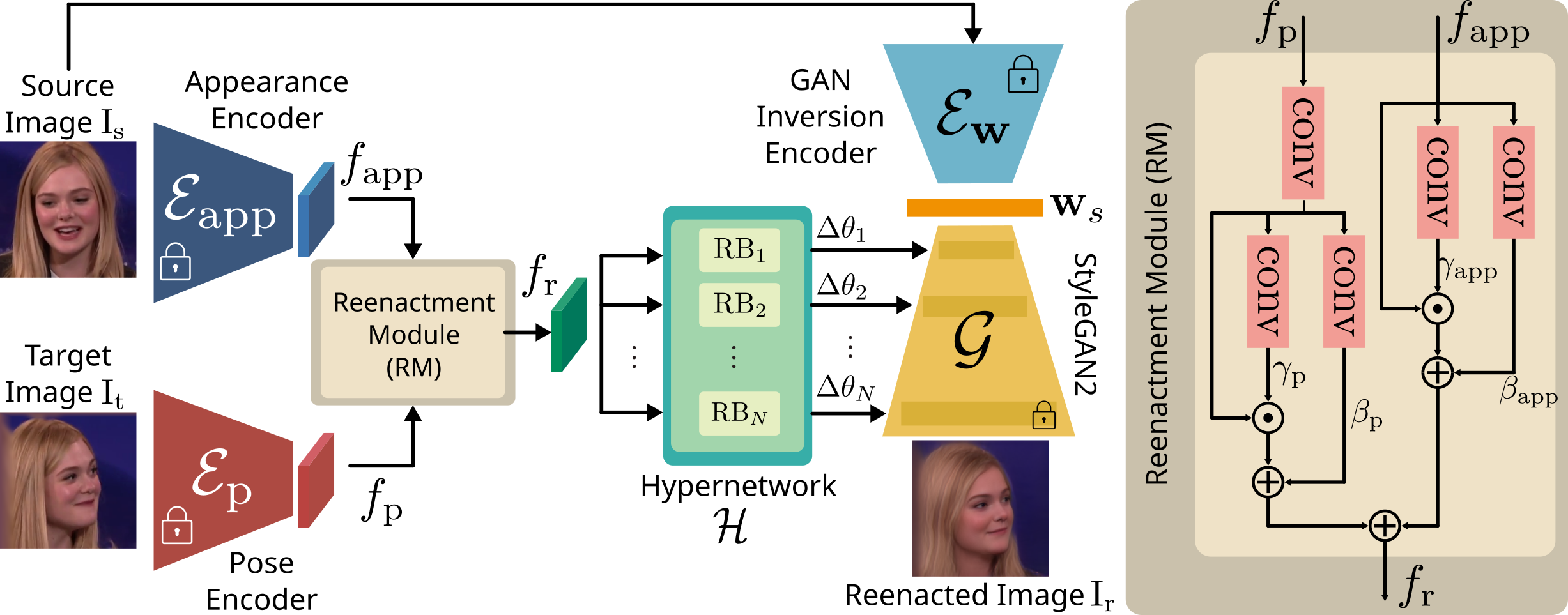
We present a method for neural face reenactment that jointly learns to refine and re-target the facial images using a pretrained StyleGAN2 model and a hypernetwork. Given a source ($\mathrm{I}_s$) and a target ($\mathrm{I}_t$) image, we first extract the source appearance features, $f_{\mathrm{app}}$, and the target pose features, $f_{\mathrm{p}}$, using the appearance ($\mathcal{E}_{\mathrm{app}}$) and the pose ($\mathcal{E}_{\mathrm{p}}$) encoders, respectively. The Reenactment Module (RM) learns to effectively fuse these features, producing a feature map $f_{\mathrm{r}}$ that serves as input into each Reenactment Block (RB) of our hypernetwork module $\mathcal{H}$. The predicted offsets, $\Delta\theta$, update the weights of the StyleGAN2 generator $\mathcal{G}$ so that using the inverted latent code $\mathrm{w}_\mathrm{s}$ generates a new image $\mathrm{I}_{\mathrm{r}}$ that conveys the identity characteristics of the source face and the facial pose of the target face. We note that, during training, the encoders $\mathcal{E}_{\mathrm{app}}$, and $\mathcal{E}_{\mathrm{p}}$, along with the generator $\mathcal{G}$ are kept frozen, and we optimize only the Reenactment Module (RM) and the hypernetwork module $\mathcal{H}$.
@InProceedings{bounareli2023hyperreenact,
author = {Bounareli, Stella and Tzelepis, Christos and Argyriou, Vasileios and Patras, Ioannis and Tzimiropoulos, Georgios},
title = {HyperReenact: One-Shot Reenactment via Jointly Learning to Refine and Retarget Faces},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year = {2023},
}