
Video-driven neural face reenactment aims to synthesize realistic facial images that successfully preserve the identity and appearance of a source face, while transferring the target head pose and facial expressions. Existing GAN-based methods suffer from either distortions and visual artifacts or poor reconstruction quality, i.e., the background and several important appearance details, such as hair style/color, glasses and accessories, are not faithfully reconstructed. Recent advances in Diffusion Probabilistic Models (DPMs) enable the generation of high-quality realistic images. To this end, in this paper we present DiffusionAct, a novel method that leverages the photo-realistic image generation of diffusion models to perform neural face reenactment. Specifically, we propose to control the semantic space of a Diffusion Autoencoder (DiffAE), in order to edit the facial pose of the input images, defined as the head pose orientation and the facial expressions. Our method allows one-shot, self, and cross-subject reenactment, without requiring subject-specific fine-tuning. We compare against state-of-the-art GAN-, StyleGAN2-, and diffusion-based methods, showing better or on-par reenactment performance.
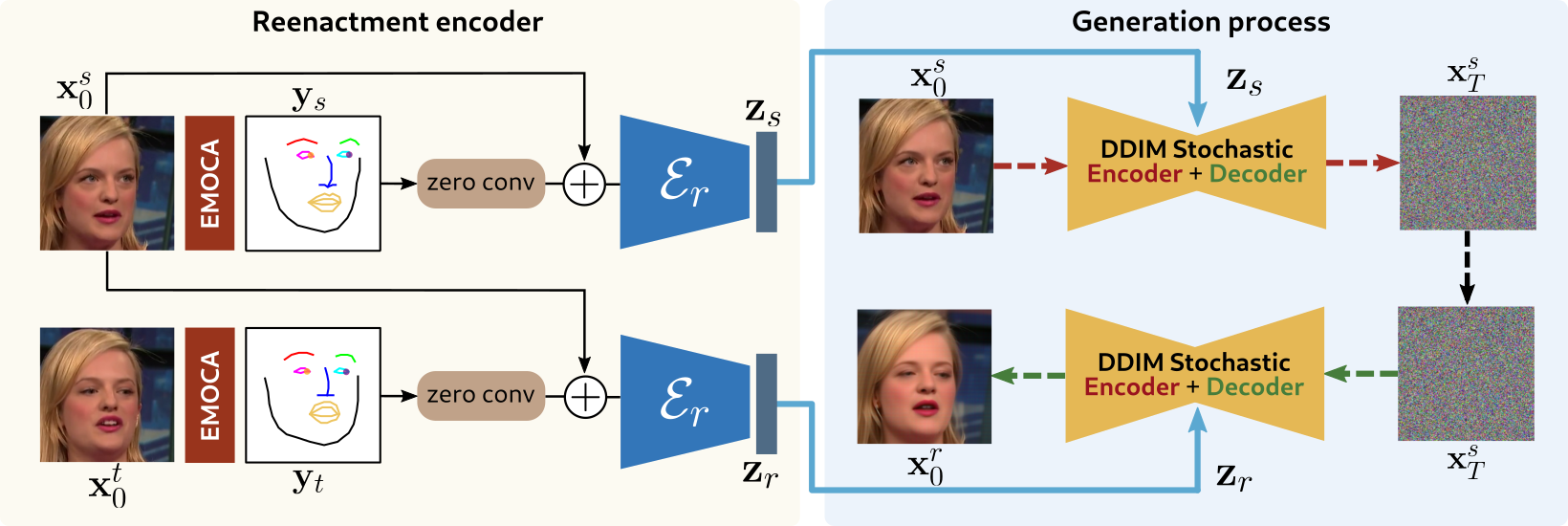
We present a method for neural face reenactment based on a pre-trained Diffusion Probabilistic Model (DPM). Specifically, given a pair of a source ($\mathbf{x}_0^s$) and a target ($\mathbf{x}_0^t$) images, we propose to condition the pre-trained semantic encoder of a Diffusion Autoencoder (DiffAE) model on the target facial landmarks $\mathbf{y}_t$. Our reenactment encoder $\mathcal{E}_r$ learns to to predict the semantic code $\mathbf{z}_r$ that, when decoded by the pre-trained DDIM sampler, generates the reenacted image $\mathbf{x}_0^r$ that captures the source identity/appearance and the target head pose and facial expressions.
@InProceedings{bounareli2024diffusionact,
author = {Bounareli, Stella and Tzelepis, Christos and Argyriou, Vasileios and Patras, Ioannis and Tzimiropoulos, Georgios},
title = {DiffusionAct: Controllable Diffusion Autoencoder for One-shot Face Reenactment},
journal = {IEEE Conference on Automatic Face and Gesture Recognition},
year = {2025},
}